1. エージェントにおけるメモリと知識
エージェントが扱う情報は、大きく以下の4つに分類できる。
- 短期メモリ: セッション内の会話履歴を保持し、直近の文脈を理解する。
- 長期メモリ: セッションを跨いで保持され、ユーザーの好みや重要な事実などを記憶する。
- 学習済み知識 :モデルに事前学習やファインチューニングによって組み込まれている静的な知識。
- 検索された知識 : API、データベース、文書などの外部ソースから実行時に動的に取得される知識。
2. 短期メモリ(ワーキングメモリ)の管理
エージェントに会話の流れを把握させるための基本的な手法。
(1) 手動でのメッセージ追跡
Runner.run_sync を使用する際、メッセージのリスト(ResponseInputItem)を保持し、新しいやり取りが発生するたびにリストへ追加してモデルに渡す。
(2) Sessionsクラスによる自動化
OpenAI Agents SDKの Sessions クラス(特に SQLiteSession)を使用すると、会話履歴の保存、呼び出し、編集が自動化される。session_id を指定することで、ユーザーごとに独立した会話空間を維持できる。
3. 大規模な会話スレッドの管理
会話が長くなると、モデルのコンテキストウィンドウ(入力制限)を超過したり、処理速度が低下したりする問題が発生する。これを解決するため、以下の2つの手法がある。
- スライディング・メッセージ・ウィンドウ(Sliding message window):最新のX件のメッセージのみを保持し、古いメッセージを破棄する方式(先入先出法)。実装は容易だが、重要な文脈が失われる可能性がある。
- メッセージ要約(Message summarization): 古いメッセージをそのまま捨てるのではなく、LLMを使って要約し、コンパクトな形で文脈として残す方法。文脈の連続性を保ちつつ、トークン数を抑えられる利点がある。
4. 長期メモリと構造化メモリ・リコール
単なる履歴の保存ではなく、特定の事実やユーザーの好みを永続的に保存する手法。
- 永続化されたメッセージログ(Persistent message logs):
SQLiteSessionにdb_pathを指定することで、プログラムを終了しても会話履歴をローカルに保存できる。 - 構造化メモリ(Structured memory recall):会話履歴をすべて保存するのではなく、重要な事実を抽出し、JSON形式などで保存・読み込む。エージェントには save_memory や load_memory といったツール(FunctionTool)を与え、必要に応じて自律的に記憶を管理させる。
5. 外部知識の活用とRAG
モデルの学習データに含まれない最新情報やプライベートな情報を扱う手法。
(1) 構造化データの検索
API(例:仮想通貨の価格取得)やデータベースからのクエリ実行を通じて、動的に情報を取得し、回答に組み込む。
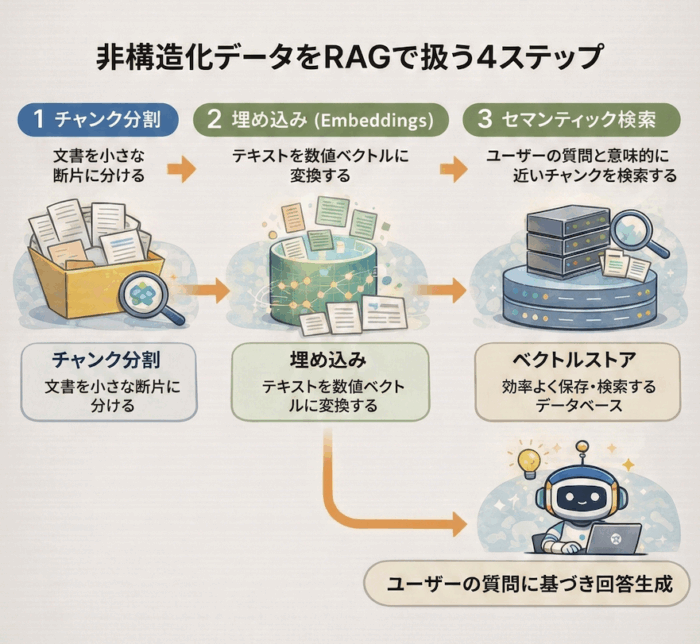
(2) 非構造化データとRAG(検索拡張生成)
文書ファイルなどの非構造化データを扱うために、以下のステップで RAG を実装する。
- チャンク分割: 文書を小さな断片に分ける。
- 埋め込み(Embeddings): テキストを数値ベクトルに変換する。
- セマンティック検索: ユーザーの質問と意味的に近いチャンクを検索する。
- ベクトルストア: ベクトルデータを効率よく保存・検索するデータベース。
OpenAI Agents SDK では FileSearchTool を使うことで、文書のインジェストから検索までの一連の流れを大幅に簡略化できる。
6. 実装の限界と注意点
ナレッジベース(外部の検索可能な知識)を用いたエージェントには、以下のような落とし穴がある。
- 曖昧な質問: ユーザーの意図が不明瞭だと、誤った検索結果を導く可能性がある。
- 情報の不在: ナレッジベースに答えがない場合、モデルがハルシネーションを起こすリスクがある。
- 情報の競合: 複数のソースから矛盾する情報が見つかった場合、適切な優先順位付けが必要になる。