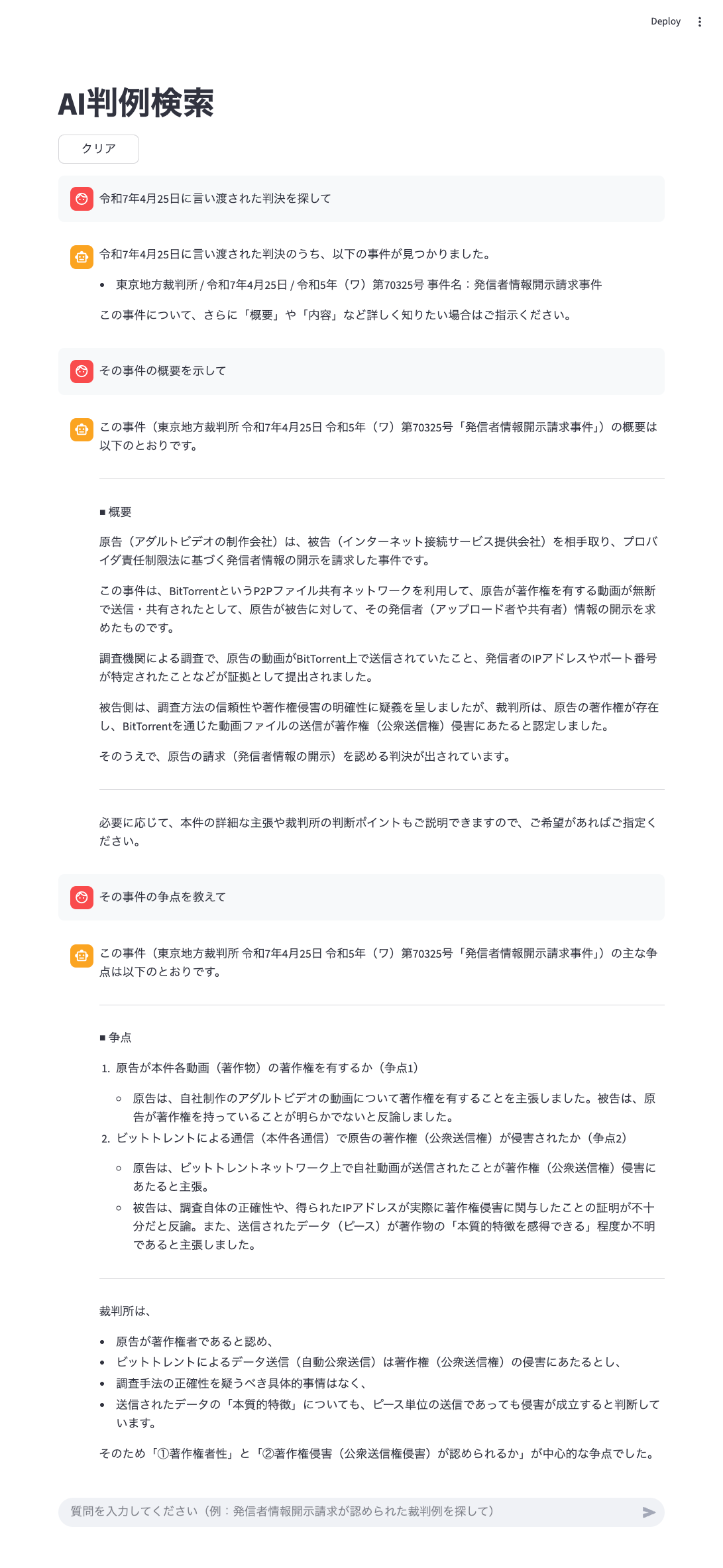
Chatgptで生成した判例検索用Pythonコード。自然言語でデータベース内の裁判例を絞り込み、その内容について質問できる。サンプルはWestlaw掲載の裁判例から抽出した。実行にはAPIkeyが必要となる。
1. DB検索ツール+エージェント本体(database_query.py)
# database_query.py
from __future__ import annotations
import sqlite3
from pathlib import Path
from typing import List, Optional, Tuple
from pydantic import BaseModel, Field
from agents.agent import Agent
from agents.run import Runner
from agents.tool import function_tool
# =====================
# DB 接続
# =====================
DB_PATH = Path("cases.db")
def _connect() -> sqlite3.Connection:
if not DB_PATH.exists():
raise FileNotFoundError(f"DB not found: {DB_PATH.resolve()}")
conn = sqlite3.connect(str(DB_PATH))
conn.row_factory = sqlite3.Row
return conn
# =====================
# 1) 検索ツール
# =====================
class CaseSearch(BaseModel):
keywords: str = Field(..., description="検索語(スペース区切り)")
court: Optional[str] = Field(None, description="裁判所名(部分一致)")
limit: int = Field(5, ge=1, le=20, description="最大件数")
@function_tool
def search_cases(q: CaseSearch) -> str:
"""
cases テーブルを全文 LIKE 検索し、ヒットした裁判例の一覧を返す。
"""
keywords = [k.strip() for k in q.keywords.split() if k.strip()]
if not keywords:
return "検索語が空です。"
where_parts: List[str] = []
params: List[object] = []
for kw in keywords:
where_parts.append(
"("
"doc_id LIKE ? OR court LIKE ? OR date LIKE ? "
"OR case_number LIKE ? OR case_name LIKE ? "
"OR main_text LIKE ? OR facts_and_reasons LIKE ?"
")"
)
like = f"%{kw}%"
params.extend([like] * 7)
if q.court:
where_parts.append("court LIKE ?")
params.append(f"%{q.court}%")
sql = f"""
SELECT doc_id, court, date, case_number, case_name
FROM cases
WHERE {" AND ".join(where_parts)}
ORDER BY date DESC
LIMIT ?
"""
params.append(int(q.limit))
with _connect() as conn:
rows = conn.execute(sql, params).fetchall()
if not rows:
return "該当なし。"
lines = []
for i, r in enumerate(rows, 1):
lines.append(
f"{i}. doc_id={r['doc_id']} / {r['court']} / {r['date']} / "
f"{r['case_number']} / {r['case_name']}"
)
return "\n".join(lines)
# =====================
# 2) 本文取得ツール
# =====================
class CaseGet(BaseModel):
doc_id: str = Field(..., description="cases.doc_id(完全一致)")
include_facts_and_reasons: bool = Field(True, description="理由部分も返すか")
@function_tool
def get_case_text(q: CaseGet) -> str:
"""
doc_id を指定して、裁判例本文を取得する。
"""
with _connect() as conn:
row = conn.execute(
"""
SELECT doc_id, court, date, case_number, case_name,
main_text, facts_and_reasons
FROM cases
WHERE doc_id = ?
""",
(q.doc_id,),
).fetchone()
if not row:
return f"doc_id={q.doc_id} は見つかりませんでした。"
header = (
f"doc_id: {row['doc_id']}\n"
f"court: {row['court']}\n"
f"date: {row['date']}\n"
f"case_number: {row['case_number']}\n"
f"case_name: {row['case_name']}\n"
)
body = row["main_text"] or ""
reasons = row["facts_and_reasons"] or ""
if q.include_facts_and_reasons and reasons.strip():
return header + "\n[main_text]\n" + body + "\n\n[facts_and_reasons]\n" + reasons
return header + "\n[main_text]\n" + body
# =====================
# 3) 参照解決ツール
# =====================
class CaseResolve(BaseModel):
court: Optional[str] = Field(None)
date: Optional[str] = Field(None)
case_number: Optional[str] = Field(None)
case_name: Optional[str] = Field(None)
limit: int = Field(5, ge=1, le=10)
@function_tool
def resolve_case_doc_id(q: CaseResolve) -> str:
"""
会話文脈中のメタ情報から doc_id 候補を解決する。
優先順位:事件番号 > 事件名(+裁判所) > 裁判所(+日付)
"""
where_parts: List[str] = []
params: List[object] = []
if q.case_number:
where_parts.append("case_number LIKE ?")
params.append(f"%{q.case_number}%")
elif q.case_name:
where_parts.append("case_name LIKE ?")
params.append(f"%{q.case_name}%")
if q.court:
where_parts.append("court LIKE ?")
params.append(f"%{q.court}%")
else:
if q.court:
where_parts.append("court LIKE ?")
params.append(f"%{q.court}%")
if q.date:
where_parts.append("date LIKE ?")
params.append(f"%{q.date}%")
if not where_parts:
return "参照解決に必要な手がかりが不足しています。"
sql = f"""
SELECT doc_id, court, date, case_number, case_name
FROM cases
WHERE {" AND ".join(where_parts)}
ORDER BY date DESC
LIMIT ?
"""
params.append(int(q.limit))
with _connect() as conn:
rows = conn.execute(sql, params).fetchall()
if not rows:
return "候補が見つかりませんでした。"
lines = ["候補:"]
for i, r in enumerate(rows, 1):
lines.append(
f"{i}. doc_id={r['doc_id']} / {r['court']} / {r['date']} / "
f"{r['case_number']} / {r['case_name']}"
)
return "\n".join(lines)
# =====================
# 4) エージェント定義
# =====================
FORCE_REFERENCE_RULES = """【参照指示の強制ルール】
「概要」「その事件」「その判決」等が含まれる場合は、
resolve_case_doc_id → get_case_text を必ず実行すること。
"""
case_agent = Agent(
name="CaseDBHelper",
instructions=(
"あなたは判例DB検索アシスタント。\n"
"必ずツールで確認できた事実のみを用いて回答せよ。\n\n"
"検索依頼には search_cases、\n"
"参照指示には resolve_case_doc_id と get_case_text を用いる。\n\n"
+ FORCE_REFERENCE_RULES
),
tools=[search_cases, resolve_case_doc_id, get_case_text],
)
HistoryItem = Tuple[str, str]
def _build_input(question: str, history: List[HistoryItem], max_turns: int = 8) -> str:
lines: List[str] = []
for u, a in history[-max_turns:]:
lines.append(f"ユーザー: {u}")
lines.append(f"アシスタント: {a}")
lines.append(f"ユーザー: {question}")
return "\n".join(lines)
def run_agent(question: str, history: Optional[List[HistoryItem]] = None) -> str:
prompt = _build_input(question, history or [])
result = Runner.run_sync(case_agent, prompt)
return result.final_output2. UI(streamlit_app.py)
# streamlit_app.py
import streamlit as st
from database_query import run_agent
st.set_page_config(page_title="AI判例検索", layout="wide")
st.title("AI判例検索")
# =====================
# セッション初期化
# =====================
if "chat" not in st.session_state:
st.session_state.chat = []
# =====================
# 操作ボタン
# =====================
col1, col2 = st.columns([1, 6])
with col1:
if st.button("クリア", use_container_width=True):
st.session_state.chat = []
st.rerun()
# =====================
# 履歴表示
# =====================
for u, a in st.session_state.chat:
with st.chat_message("user"):
st.write(u)
with st.chat_message("assistant"):
st.write(a)
# =====================
# 入力
# =====================
question = st.chat_input("質問を入力してください")
if question:
with st.chat_message("user"):
st.write(question)
with st.chat_message("assistant"):
with st.spinner("検索中..."):
answer = run_agent(question, history=st.session_state.chat)
st.write(answer)
st.session_state.chat.append((question, answer))3. 判例データサンプル(cases.db)
| doc_id | court | date | case_number | case_name | main_text | facts_and_reasons | source_pdf | extracted_at |
|---|---|---|---|---|---|---|---|---|
| WLJP_Hanrei_2025WLJPCA03079003_20251229_1255 | 東京地方裁判所 | 令和7年3月7日 | 令和6年(ワ)第70278号 | 発信者情報開示請求事件 | 被告は、原告に対し、別紙発信者情報目録記載の各情報を開示せよ。訴訟費用は被告の負担とする。 | 請求主文同旨。事案の概要 本件は、原告が、自身の著作物がBitTorrentネットワークを通じて公衆送信されたとして、プロバイダ責任制限法に基づき発信者情報の開示を求めた事案である。 | inputs/WLJP_Hanrei_2025WLJPCA03079003_20251229.pdf | 2025-12-29T14:16:44 |
| WLJP_Hanrei_2025WLJPCA04259003_20251229_1256 | 東京地方裁判所 | 令和7年4月25日 | 令和5年(ワ)第70325号 | 発信者情報開示請求事件 | 被告は、原告に対し、別紙発信者情報目録記載の各情報を開示せよ。 | 請求主文同旨。事案の概要 本件は、アダルト動画の著作権侵害を理由として、BitTorrentによる公衆送信に関する発信者情報開示請求がなされた事案である。 | inputs/WLJP_Hanrei_2025WLJPCA04259003_20251229.pdf | 2025-12-29T14:19:41 |
| WLJP_Hanrei_2025WLJPCA03079005_20251229_1255 | 東京地方裁判所 | 令和7年3月7日 | 令和6年(ワ)第70052号 | 発信者情報開示命令の申立てについての決定に対する異議事件、発信者情報開示請求反訴事件 | 原告の請求を棄却する。 | 請求の趣旨及び理由 本件は、発信者情報開示命令に対する異議申立てと、それに付随する反訴が併合審理された事案である。 | inputs/WLJP_Hanrei_2025WLJPCA03079005_20251229.pdf | 2025-12-29T14:17:45 |
| WLJP_Hanrei_2025WLJPCA03076006_20251229_1256 | 東京地方裁判所 | 令和7年3月7日 | 令和5年(ワ)第70463号 | 発信者情報開示請求事件 | 被告は、原告に対し、別紙発信者情報目録記載の各情報を開示せよ。 | 請求主文同旨。事案の要旨 本件は、著作権侵害を理由としてプロバイダに対する発信者情報開示請求がなされた事案である。 | inputs/WLJP_Hanrei_2025WLJPCA03076006_20251229.pdf | 2025-12-29T14:14:15 |4. ファイル配置
my_case_app/
├─ streamlit_app.py # UI(Streamlit)
├─ database_query.py # DB検索ツール+エージェント本体
└─ cases.db # 判例データ(SQLite)5. 実行
streamlit run streamlit_app.py6. 実行例