Agents SDKを使った判例検索コード( database_query.py )解析の2回目。今回はこのコードの「 検索ツール 」部分について、1行ずつその働きを見ていく。
class CaseSearch(BaseModel):PythonのPydanticライブラリを使用して、データの構造(スキーマ)を定義している。具体的には、CaseSearch(判例検索)という名前のデータモデルを作成しようとしている。
1. 各要素の意味
class CaseSearch:CaseSearchという名前の新しいクラス(データのひな形)を作る。(BaseModel):Pydanticが提供するBaseModelというクラスを継承している。これにより、このクラスは単なるデータの集まりではなく、型チェックやバリデーション(妥当性確認)の機能を備えるようになる。
2. なぜPydanticを使うのか?
Pydanticの BaseModel を使うと、以下のようなことが自動でできるようになるから。
- データ型の強制:指定した型と違うデータが入ってきたときにエラーを出してくれる。
- 構造の定義:「判例検索にはキーワード(string)と年代(int)が必要」といったルールを明確に定義できる。
- 変換が容易:JSONデータをPythonのオブジェクトに変換したり、その逆を行ったりするのが簡単になる。
keywords: str = Field(..., description="検索語(スペース区切り)")Pydanticのモデル内で以下のようなフィールド(属性)の詳細なルールを定義している。
| パーツ | 意味 |
keywords: str | 変数名が keywords で、型は文字列(string)であることを示す。 |
Field(...) | Pydanticの Field 関数。バリデーション(検証)ルールやメタデータを設定するために使う。 |
... (Ellipsis) | フィールドが必須項目であることを意味する。データを作る際にこれを省略するとエラーになる。 |
description="検索語(スペース区切り)" | 項目の説明文。AIは description を読んで「ここにはスペース区切りの検索語を入れればいいんだな」と理解する。これにより、AIが正しい形式でデータを生成してくれるようになる。 |
court: Optional[str] = Field(None, description="裁判所名(部分一致)")courtという変数について、 keywords とは対照的に、あってもなくても良い(任意項目)というルールを定義している。特に裁判所の名前のようにユーザーが指定する場合もあれば、指定しない場合もあるデータを扱うのに適した書き方である。
| パーツ | 意味 |
Optional[str] | str(文字列)または None(空)のどちらでも良いことを示している |
Field(None, ...) | 最初の引数が None になっているため、デフォルト値は None(空)となる。これにより、データ作成時にこの項目を省略してもエラーにならない。 |
description="裁判所名(部分一致)" | AIに対して、この項目が裁判所名であり、部分一致での検索が可能であることを伝えている。 |
limit: int = Field(5, ge=1, le=20, description="最大件数")検索結果の件数を制御するための変数(limit)に関する設定。単なる数値指定ではなく、入力される値に制限(バリデーション)をかけているのが特徴。これにより、システムが想定外の負荷を受けたり、エラーになったりするのを防いでいる。
| パーツ | 意味 |
limit: int | 変数名が limit で、整数過多(integer) であることを示している。 |
5 (第1引数) | デフォルト値が5であることを示す。ユーザーが件数を指定しなかった場合、自動的に 5 が設定される。 |
ge=1 | Greater than or equal to の略。limitが1以上である必要があることを示している。 |
le=20 | Less than or equal to の略。limitが20以下である必要があることを示している。 |
description="最大件数" | AIに対し、limit=取得するデータの最大件数であることを伝えている。 |
@function_tool
def search_cases(q: CaseSearch) -> str:上で作成した Pydantic モデル(CaseSearch)を、AIエージェントが実際に道具(ツール)として使えるように登録している。各要素の意味は以下のとおり。
@function_tool(デコレータ)
この関数が単なる関数ではなく、AIエージェントが呼び出せるツールであることを宣言している。デコレータを付けることで、SDKは関数の名前、引数の型、説明文を自動的に解析し、AIに「こんなツールが使えますよ」と伝えてくれる。
q: CaseSearch(引数の型指定)
引数 q に対して、先ほど定義した CaseSearch クラスを型として指定している。これにより、AIは CaseSearch で定義した keywords, court, limit という項目を正しい形式(JSON)で生成しなければならないというルールを理解する。Pydantic で書いた description や ge=1 といった制約も、この時に AI への指示書として一緒に送られる。
-> str(戻り値の型)
この関数を実行した結果、最終的に文字列(string)が返されることを示している。通常は、データベースから検索した判例の一覧などが文字列として AI に戻される。
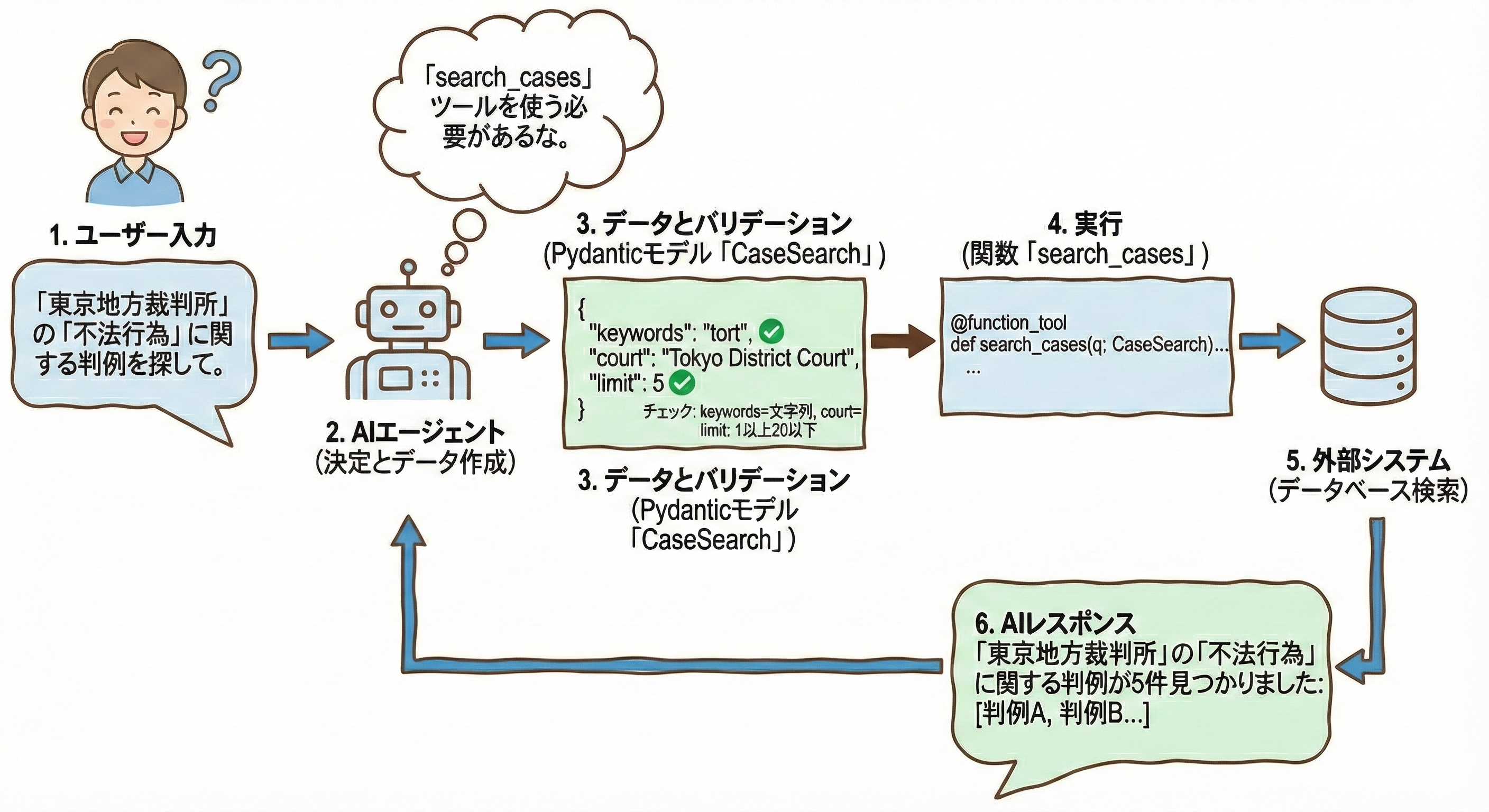
◼︎処理の流れ(イメージ図)
AIが「東京地裁の不法行為の判例を探して」とユーザーに言われた時の動きは以下のようになる。
- AIの判断:「判例を探す必要があるな。
search_casesというツールを使おう」 - データの作成:
CaseSearchモデルに従い、{"keywords": "不法行為", "court": "東京地裁", "limit": 5}というデータを作成。 - バリデーション:作成されたデータが Pydantic モデル(
ge=1など)に違反していないかチェック。 - 実行
:search_cases(q)が呼び出され、実際の検索処理(DBへのアクセス)が行われる。 - 回答:検索結果の文字列が AI に戻り、AIがそれを元にユーザーへ回答を作成。
"""
cases テーブルを全文 LIKE 検索し、ヒットした裁判例の一覧を返す。
"""上のトリプルクォートで囲まれた部分は、Pythonのドキュメント文字列(docstring)と呼ばれる。通常のプログラムで docstring は「開発者向けのメモ」に過ぎないが、@function_tool と組み合わされた場合、AIエージェントがそのツールを「いつ、何のために使うべきか」を判断するための説明書として機能する。
1. 文言の具体的な意味
cases テーブル:データベースの中に「cases(事件/裁判例)」という名前の表があり、そこにデータが格納されていることを示唆している。全文 LIKE 検索:SQLという言語で使われるLIKE演算子(パターンマッチング)を用いて、キーワードが含まれているかどうかを検索する仕組みのこと。ヒットした裁判例の一覧を返す:検索の結果、条件に合うデータをリスト形式(文字列)で出力することを明示している。
2. AIエージェントにおけるdocstringの役割
@function_tool を使っている場合、この説明文はプログラムの実行には直接関係しないものの、AIの挙動を決定づける。たとえば、ユーザーが「過去の判決を教えて」と言ったとき、AIはこのドキュメントを見て「search_cases 関数に『裁判例の一覧を返す』と書いてあるから、これを使おう!」と判断する。プロンプトの一部として送信されるこの説明文は、内部的にAIへの命令文(システムプロンプト)に組み込まれるため、ここを詳しく書けば書くほど、AIはツールの使い時を間違えなくなる。